Dr. Neil's Notes
Software > Development
Explicit Code
Introduction
Interesting changes are afoot. When I started writing code, a memory block was used to store values, a string was a character array, and a character was a byte (ok, sometimes 7 bits), and a number was a collection of bytes, depending on how big the number was, a word (2 bytes), a double (4 bytes). Memory was allocated, data was stored, and you the programmer, needed to know what sort of data was stored in the location in memory. Then along came languages that wanted an explicit syntax to identify the type of contents in a memory location. Code became more maintainable and readable. A programmer returning to code 2 years after it was written could instantly see what type of data was stored in a variable, a character, an integer, a floating point number.
Modern compilers are smart enough to work this out at compile time and we have gone back to code that tells you nothing about the type to expect in a method, or function.
All software projects (worth discussing) grow, age, and extend functionality, and fix issues discovered. Through the period of time that the software is maintained, and enhanced, the level of complexity of the code tends to increase. Even with highly disciplined approaches to refactoring and tidying of the code, an increase in features, will lead to increased complexity. Adding to this complexity is the need for backwards compatibility, support for integrations, evolving platforms, changing SDKs, and new operating system versions. Over time all software of value to organizations tends to get harder to work with.
The code comment
In the past I have not been a fan of code comments, the view often held by programmers is that code should be easy to read. If asked this question ten years ago I would probably have said the same thing as many developers arguing against writing comments in code; "if you want to know what code is doing then read the code". This relies on several truths; i) the code should be human readable, ii) the complexity of the code must be low enough for the developer to comprehend the intention, iii) the code is working as intended when written.
Changes in how developers write code have meant that we often have none of these truths in place.
Consider this simple method:
public void DoWork()
{
var a = Factory.GetContainer();
a.MyProperty = 1;
var b = Factory.GetContainer();
b.MyProperty = 2;
a.Add(b);
}
What does this code do?
Do you need to investigate the Factory.GetContainer method ?
Do you need to investigate the Add method? On what type of object ?
Code like this leaves clues that need to be followed, and is not explicitly telling the future programmer (that might be you) what the code is doing. This is a very simple example, however the world is littered with code like this. Extra effort is required each step of the way to understand what the code is doing. Once you do dig into the different methods being called and discover what the code is doing, without any comments, you have not got any idea if this was the intention of the code author.
One way to help resolve this is to apply religious and strict Test Driven Development (TDD). Not a single line of code is written, without a unit test being written that requires that line of code. The unit tests then supply some level of intention definition of the code. However the unit tests must also be written to show what the code is not intended to do, and then you might need to read through 20 tests to understand what this DoWork method is intended to do. More work again. Do not get me wrong, TDD is the current best practice I have found for developing robust code. However I am now also a fan of code comments explaining what the method is supposed to be doing, the intention. It makes reading the code much faster and easier, it also lets you check the comment is correct.
In the C# code method example you will also notice that the method is public. This means other objects will be calling this method on an instance of the class. Over time large software projects develop many libraries, containing many classes, with public methods. As the code evolves, and new functions are added, you want to make the manipulation of the code as simple as possible.
In most modern IDEs when you type an object instance variable name and then press a key combination you will see a collection of methods that can be called on that object instance. In Visual Studio this is called Intellisense. It is useful for developers working with complex code libraries.
This is where the triple line (/// in C#) comments become useful in your code. They get used by the IDE to help the developer navigate the available methods in the class being used.
With no comments the programmer sees this:
With comments the programmer will see this:

As your code grows and extends, you will find you have code libraries that can be used in places for which they were not originally designed. This is known as code reuse and a good thing. However it is also good to help all the developers working on the code to know what to expect from using a method, property, or event in a class you are writing.
Good code comments will help future developers understand how to work with the code you have written.
One of the reasons many developers push back against adding comments into code is that the comments get out of date. The code gets modified, and the comments do not. It is for this reason that every code review should be reviewing the code and the comments, and the documentation. With modern source control systems, and practices like Pull Requests (PR) in Git, this is easier to manage. A PR can be approved only when the reviewers can see the code and the comments are updated.
The var problem
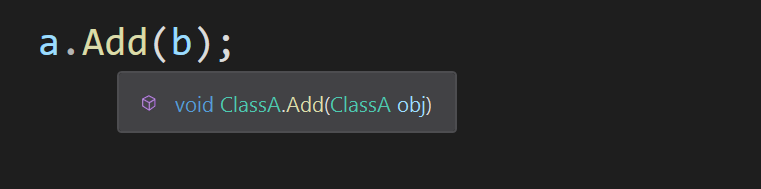
Next I want to discuss another challenge I see emerging in code, relating to readability. In the method example shown above, what is the type of the variable a and b ? When code is simple it is probably easy to determine this, and the IDE might help, in Visual Studio when you mouse over a var you can see a tooltip with the type.

This is great, until you are 4 levels deep into a stack trace and trying to work out what type a variable is relating to code you have open in 2 other windows. Have you jumped back and forth between code multiple times trying to keep all the types you found in the IDE tooltip in your mind at the same time? Then you will know why explicit definition of a type in code is useful.
To make matters worse, when code grows and libraries get used in multiple places then tracking the usage can be made harder by using var instead of explicitly stating the type. Using the compiler to determine where something might break is no longer possible as demonstrated in the following (simplified) example.
Imagine you have a Worker class with the method shown already
public class Worker
{
public void DoWork()
{
var a = Factory.GetContainer();
a.MyProperty = 1;
var b = Factory.GetContainer();
b.MyProperty = 2;
a.Add(b);
Console.WriteLine(a.MyProperty);
}
}
The Factory class returns instances of a class to work with
public class Factory
{
public static ClassA GetContainer()
{
return new ClassA();
}
}
ClassA is defined as
public class ClassA
{
public int MyProperty { get; set; }
public void Add(ClassA obj)
{
MyProperty += obj.MyProperty;
}
}
When you compile and run the code you see the result:
❯ dotnet run
Doing work
3
Now imagine this is all part of a huge code base that has thousands of code libraries, and tens of thousands of methods. You have been shown this code and asked to change the way it works, We need to replace the ClassA with a new ClassB that works as we now want.
You define the new class as per the spec you have been given (maybe you even write unit tests first to validate how you want it to work), you end up with this new ClassB and submit it for a code review.
public class ClassB
{
public int MyProperty { get; set; }
public void Add(ClassB obj)
{
MyProperty = int.Parse($"{this.MyProperty}{obj.MyProperty}");
}
}
The code gets reviewed and after some questions about this being the best way to concatenate two integers, this is approved.
Now you need to change the Factory to return new types of ClassB rather than ClassA.
public class Factory
{
public static ClassB GetContainer()
{
return new ClassB();
}
}
The code compiles and runs providing the result you wanted.
❯ dotnet run
Doing work
12
Great, you push this to a code review as part of a Pull Request into the main branch. It passes and you have got the change into the main branch of the library.
What you do not know is that somewhere else in the code the same Factory is being used and that part of the code did not want the new behaviour, they were happy with numeric addition and were not interested in the concatenation of the numbers. However the code compiled fine and was pushed into production with this new defect. This could have easily been prevented by not using var, and instead explicit types.
When you find the code that you never knew existed before it looks like this:
public class OldWorker
{
public void DoWork()
{
var a = Factory.GetContainer();
a.MyProperty = 1;
var b = Factory.GetContainer();
b.MyProperty = 2;
a.Add(b);
Console.WriteLine(a.MyProperty);
}
}
It compiles with the new code changes and no longer works as before. This could have been prevented by using explicit types in the code. If the code had looked like this, then the latest changes would have failed to compile.
public class OldWorker
{
public void DoWork()
{
ClassA a = Factory.GetContainer();
a.MyProperty = 1;
ClassA b = Factory.GetContainer();
b.MyProperty = 2;
a.Add(b);
Console.WriteLine(a.MyProperty);
}
}
The compilation failure would get picked up quickly and you would have been able to address this scenario differently.
While this is a highly simplified example, consider how this can impact your code over time as functionality changes are requested.
I would always prefer a the compiler to fail rather than ship software that does not work as expected.
Of course in this simple example I would expect a unit test to fail against the OldWorker.DoWork method. However in the more complex, and real, world of software, it is entirely possible that unit tests would pass when an algorithm is changed slightly, especially if edge cases that were not tested behave differently.
Conclusion
I would prefer to have multiple levels of protection against any potential future issue. I feel more comfortable knowing there are unit tests, code comments, and the code compiles. If our code can be written in a way to defend against potential issues, it should be written that way.